Caching issues can turn a snappy application into a sluggish mess (or a total outage) in seconds. Here are some real-world-inspired scenarios and how high-scale companies handle them.
1. Thundering Herd (The “Midnight Expiry”)
This happens when you set a fixed TTL (Time To Live) for a large batch of data.
Case Study: A major E-commerce platform during a holiday sale.
The Scenario: They cached 100,000 product descriptions at exactly 12:00 AM with a 24-hour expiry. At 12:00 AM the next day, all 100,000 cache keys expired simultaneously.
The Result: The next wave of user requests found “Cache Misses” for everything. The database was suddenly hit with 50,000+ concurrent queries to “re-warm” the cache, causing a database CPU spike to 100% and crashing the site.
The Fix:Jitter. By adding a random offset to the TTL (e.g., 24 hours + rand(0, 300) seconds), the expirations are staggered over several minutes rather than hitting all at once.
2. Cache Penetration (The “Ghost Key” Attack)
This occurs when requests are made for data that exists neither in the cache nor the database.
Case Study: A Social Media Startup under a malicious bot attack.
The Scenario: An attacker used a script to request profiles with non-existent IDs (e.g., example.com/user/-9999 or random UUIDs).
The Result: The application checked the cache (Miss) and then queried the database (Null). Since the result was null, nothing was cached. The attacker sent millions of these requests, bypassing the cache entirely and overwhelming the database disk I/O.
The Fix:Bloom Filters. They implemented a Bloom filter—a space-efficient probabilistic data structure—at the application level.
If the Bloom filter says “No,” the app rejects the request immediately without even touching the database.
3. Cache Breakdown (The “Hot Key” Collapse)
Unlike Thundering Herd, this involves a single extremely popular key (a “Hot Key”).
Case Study: A News Outlet during a breaking world event.
The Scenario: A viral news article was being requested 10,000 times per second. The cache key for that article expired.
The Result: In the few milliseconds it took for the first “miss” to fetch the data from the DB and write it back to the cache, 5,000 other concurrent requests also saw a “miss” and rushed the database for the exact same row. This is often called “Cache Stampede.”
The Fix:Mutex Locks. The first request to see a “miss” acquires a lock. Other requests for that same key are told to wait or “sleep” for a few milliseconds until the first request updates the cache.
4. Cache Crash (The “Total Blackout”)
This is the nightmare scenario where the entire caching layer (e.g., Redis cluster) goes offline.
Case Study:Facebook (2010 Outage).
The Scenario: An automated system attempted to fix a configuration error but instead triggered a feedback loop that took down their caching cluster.
The Result: With the cache down, the massive volume of traffic shifted directly to the databases. The databases, not scaled for that kind of load, buckled instantly.
The Fix:Circuit Breakers and Multi-Level Caching. Modern architectures use a “Circuit Breaker” pattern. If the cache is down, the system might serve “stale” data from a local backup or simply return an error/limited version of the site to protect the database from a total permanent crash.
It is simply a way for businesses to determine the origins for conversion. For an e-commerce business it would be lineage of user interactions with your website/app that eventually leads them to buy a product. What specific query they made to search a desired product, what products they interacted with by clicking on them, adding to cart and eventually placing an order on your website/app.
Following can be few generalised requirements for any business willing to transform realtime interactions of users into useful information to improve their respective services, recommendations et. al.
All useful engagements must be captured like authenticating, identifying user through some unique identifier. Clicking on particular entity rendered on your app, searching for content on your app, buying something from your app.
Example, Imagine how a customer usually interacts with an e-commerce site. They usually navigate through the product catalog either through category listings or by using a search feature to find their specific product they intend to purchase, once they are able to find their product, they go through the specifications, product features, add them to cart and eventually place an order. Post placing an order, supply chain comes into picture, the user finally gets the product delivered at their doorstep.
Businesses must define conversion for their product/services, for e-commerce sites it would be order placed, for video serving platforms, it would be video being watched, for digital advertisement services, it would be banner ads shown to the user, for logistics business, it would be sourcing of the product to final delivery to the customer/client.
Here we discuss few functional requirements to setup attribution pipeline for any business which can be scaled horizontally in production to meet the demands of increasing traffic, your app/website ingests.
All user engagements are translated/serialised and captured for further processing with minimal latency.
Events for a particular user session are stitched together into unique journeys.
Platform must provide channels for external system to consume attributed data with minimal latency for online consumption.
Attributed data must be batched with different window cutoffs for offline consumption in the data warehouse.
Few non-functional requirements.
Platform must be always available.
Platform must be able to handle millions of events while able to scale horizontally, for assumption 5000-10000 events per second.
Platform must be reliable and eventually consistent.
Platform must guarantee accuracy of data.
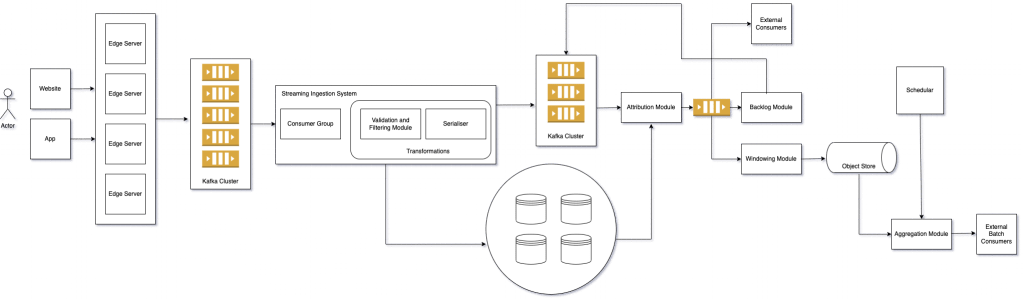
System Architecture
For example purposes we will try to map our system to an e-commerce business.
In the above scenario:
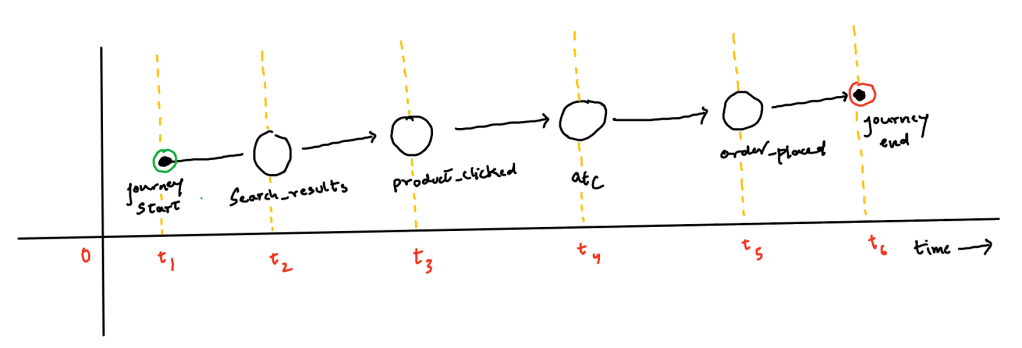
User searches for Red Tshirts.
User is shown products with ids [126, 120, 111, 110, 123, 302, 171, 189, 193, 100, 962, 899].
User clicks on product with Id 123.
User adds to cart product 123.
User places an order.
Components
Website/App
We need to integrate a client side library capable to translate well defined user interactions into beacons or tracking events to be pushed to the server.
What are tracking events/beacons?
These events are usually sent to the api servers with expectations to get HTTP 204 No Content response. Event details are usually captured and translated to query params.
In our example, we’ll have following events triggered as user interacts with the app/website.
These are REST endpoints, that transform these beacon events into a serialised object and push it to distributed log system. Serialisation format can be chosen based on the speed of serialisation/de-serialisation, the extent of compression, backward and forward compatibility if schemas of events change frequently. Usually it is preferable to choose byte data formats like Protobuf, Avro. For simplicity we will use json for our example.
Distributed log servers capture events in realtime in the form of streams, stores these events durably for a later or immediate retrieval. Most importantly these type of systems are necessarily useful for building reactive systems. Kafka is one such implementation that has all functional requirements covered for a realtime streaming pipeline. Depending on the size of the serialised events and the desired retention period, Kafka clusters can be scaled accordingly. Kafka cluster is capable of equally sharing the load for topic across brokers.
There is no hard and fast rule to decide for the retention period. If you are guaranteeing SLA of 30 mins, if the service completely goes down, retention can be configured to SLA + delta mins.
Streaming Ingestion System
Streaming ingestion system will consume events from Kafka, deserialise them. Validate and filter valid events required for attributing a particular conversion journey. Finally we need to serialise these transformed events and push them to another Kafka topic and store them in a datastore. Apache Flink being backed by a true streaming engine is perfectly suitable for a low latency event by event stream processing.
Distributed Datastore
For a realtime attribution pipeline we need a datastore which provides fast reads and writes in bulk. The datastore system must have the capability to distribute the load within its cluster and must be always available with suitable assumptions. For a high load scenario like this, Cassandra is battle tested and serves the purpose. Keeping in mind the access patterns and what events will be required to attribute a particular event in time. We may to model our tables accordingly. Partition key should be such that data gets distributed equally, informed decision before choosing a clustering key is necessary as well for faster reads from a particular node.
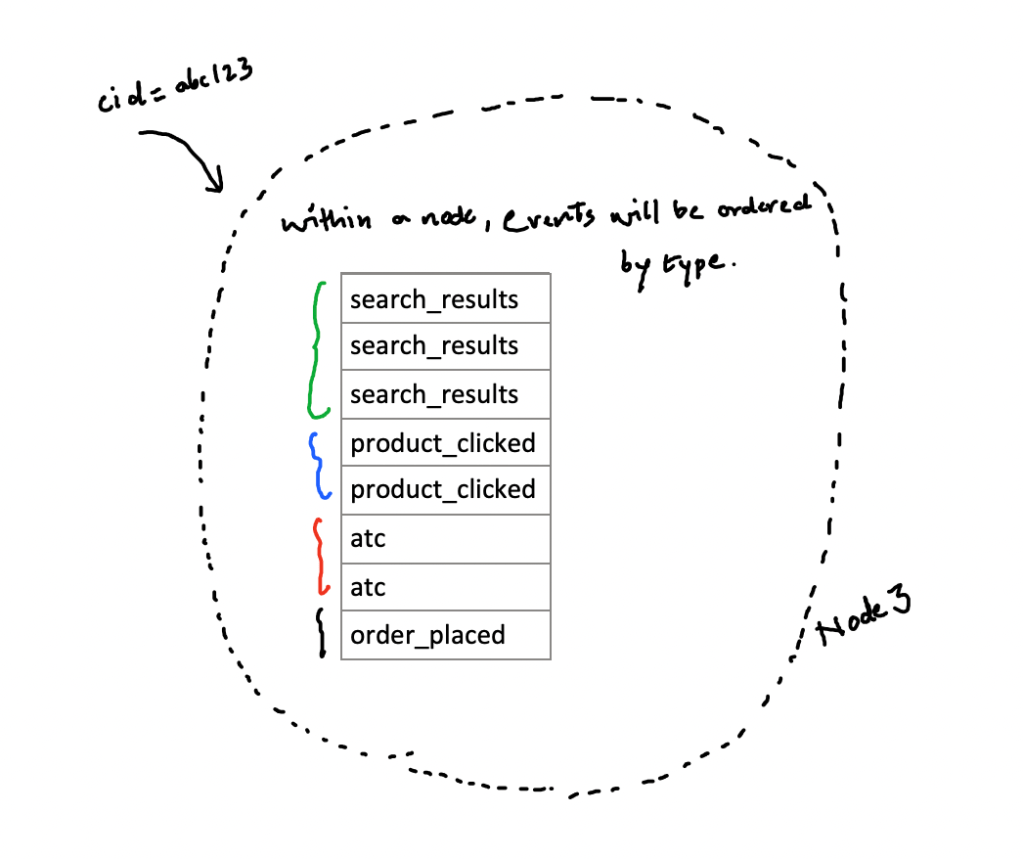
In our e-commerce example, we know that product_clicked is dependent on search_results, atc is related to product_clicked, order_placed is dependent on atc.
For our example we can distribute events across clusters using cid (customer_id) across nodes in cluster, given we assume cid is fairly random.
for clustering key we can use event_type.
Within a partition in a respective node, events would be stored in order of clustering key, in our scenario event_type
at time unit t1
E1 gets stored in Cassandra and pushed to downstream Kafka topic {cid=abc123, event_type=search_results}
at time unit t2
E2 gets stored in Cassandra and pushed to downstream Kafka topic {cid=abc123, event_type=product_clicked}
at time unit t3
E3 gets stored in Cassandra and pushed to downstream Kafka topic {cid=abc123, event_type=atc}
at time unit t4
E4 gets stored in Cassandra and pushed to downstream Kafka topic {cid=abc123, event_type=order_placed}
Attribution Module
Attribution Module is also a streaming application, that primarily encapsulates the attribution logic, it solely depends on the business needs and the relationship between events.
In our aforementioned example, following are the expected events that will get emitted in respective time units + delta time unit.
Attribution Module, emits partially attributed events, which is by choice, where it is left to the online consumers to collect and join events together for a particular journey. For generating signals for queries, we can by using the following partially attributed events, can push items with most clicks or atc to the top etc in the search results.
at time unit t1 + δ
for stitching E1 of type search_results, we do not need any pre-requisite events as it is mutually exclusive and independent event. We emit partially attributed journey at that point in time.
for stitching E2 of type product_clicked, we need search_results to attribute product_clicked event, we pull all the search_result events and try to match which list has the item clicked. We emit partially attributed journey at that point in time.
for stitching E3 of type atc, we need search_results & product_clicked to attribute atc event, we pull all the search_result, product_clicked events and try to match which clicked items has the item added to cart. We emit partially attributed journey at that point in time.
t3 + δ -> attributed_journey{cid=abc123, query=red tshirt, atc=[123]}
at time unit t4 + δ
for stitching E4 of type ordered_placed, we need search_results & product_clicked & atc events to attribute order_placed event, we pull all the search_result, product_clicked & atc events and try to match which atc items has the order placed event. We emit partially attributed journey at that point in time.
Attribution of event can fail because of many reasons Cassandra connection failure, or delay in Cassandra replication leading to reading incomplete set of events from that particular coordinator node. The failed events are stored for x time units before retrying the attribution of that event. Backlog module keeps the event for x time units in memory and register a trigger to emit the event stored in memory back to main Kafka topic, where it gets an opportunity to get attributed again for a maximum number R retries.
Windowing Module
If required, we may want to utilise the realtime streaming pipeline to generate batch data as well, for downstream jobs that still needs batch data, it could be pipelines for feature selection and daily signals for recommendation models etc. We consume partially stitched attributed events to store them to object store in partitions defined by window configuration provided, example hourly, daily etc.
Schedular & Aggregation Modules
For respective partitions (cid, query) we will try to aggregate corresponding partially stitched events into a single journey to be utilised by offline/batch pipelines. After aggregating we will have complete journey serialised.
External streaming consumers can consume partially attributed events and aggregate them using problem statement specific logic, for instance if we want to create a realtime signal for head queries (top N famous queries), we can consume these partially attributed events, partition them by query and boost items with most clicks or atcs.
External Batch/Offline Consumers
External batch/offline consumers can run their respective custom batch pipeline on aggregated data. Benefits of using realtime attribution pipeline for batch.
At the end of the window, data is immediately available, if it were a traditional batch pipeline, data will be collected till the window is completed, validations and filtering would be done. Attribution logic would be executed and finally downstream signal or feature selection pipelines will get executed.
Realtime attribution pipeline is reactive and provide data accuracy guarantee using.
Kafka – it guarantees retention of events for respective topic based on configurations.
Apache Flink – through checkpointing it can guarantee exactly once processing hence accuracy is same as that of the batch pipeline.
This is a functional setup, in production, we may have to plan for region failure through DR planning. Reconciliation logic incase system goes down for some time. Monitoring of components etc.
The following slide may help follow the flow of attribution of different events for specific journey.
Please feel free to reach out for any suggestions or any discourse.




{kind=link}
{kind=link}
{kind=link}
{kind=link}